1. Understand the problem.
Problem: A rectangular grid made up of m rows and n columns (m and n are both positive integers) has a line drawn from its top left corner to its bottom right corner (the diagonal). Given m and n, derive a formula that calculates how many squares the line passes through. Below is an illustration of the problem when m = 3 and n = 5.
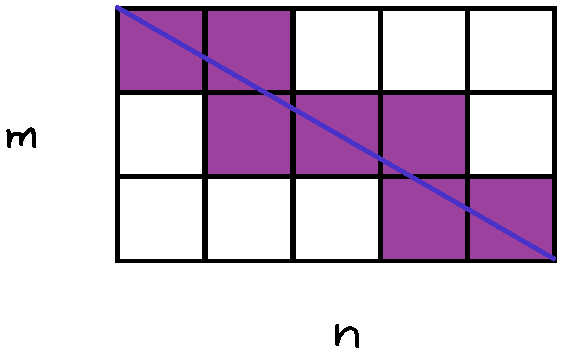
The purple squares indicate those that the line passed through. In this case, the line passes through 7 squares.
So, in essence, we are given two variables, m and n, and we are asked to produce one output, the number of squares passed through by the line.
2. Devising a plan.
I have not seen, or perhaps I have, and I just forgot, a problem similar to this, but one approach to solve it immediately comes to mind.
Plan A:
Start with small examples. Hold one variable constant and keep changing the other variable by 1, maybe a clear pattern will surface.
Professor Heap mentioned that it actually doesn't matter if the line is drawn from top left to bottom right, or from top right to bottom left, because the number of sliced squares will be the same. This prompts the approach to view the rectangular grid as two identical triangles. If we figure out the number of sliced squares inside one triangle, then we would know the number of sliced squares inside the rectangular grid.
Plan B:
View the rectangular grid as two identical triangles. It can be difficult to account for exactly how many whole squares are sliced, that is, how many whole squares can the sliced parts along the hypotenuse of the triangle make up. Moreover, there is also the possibility of an extra part dangling on its own because its counterpart is in the other triangle. Therefore, we decided that we should try to calculate the number of whole squares inside a triangle, that is, the number of squares that do not touch the diagonal line. Then, a simple subtraction, total number of squares - (number of untouched squares in a triangle)*2, can get us the answer we are looking for.
3. Carrying out the plan.
Plan A:
Plan A was fairly easy to begin. I started out by drawing 2 by 2 rectangle grids, then increased the length by 1 for a few times, as illustrated below.
First:
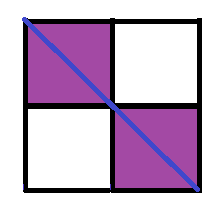
2 sliced squares
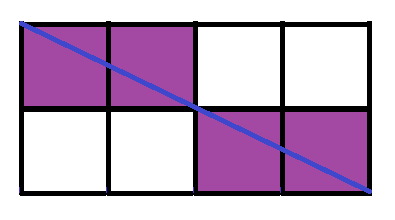
Second:
4 sliced squares
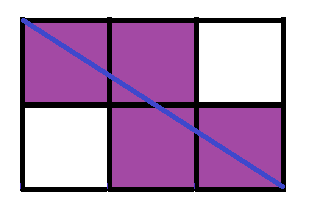
Third:
4 sliced squares
Fourth:
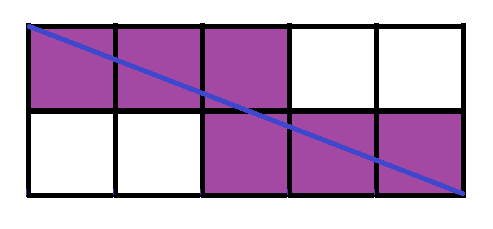
6 sliced squares
So, the pattern seems to be that starting from 2, for every increase of 2 on the length, the number of sliced squares increases by 2. Now try with various widths.
First:
6 sliced squares
Second:
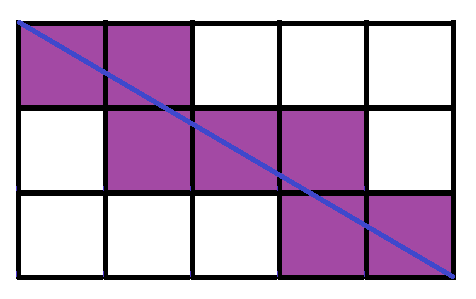
7 sliced squares
Third:
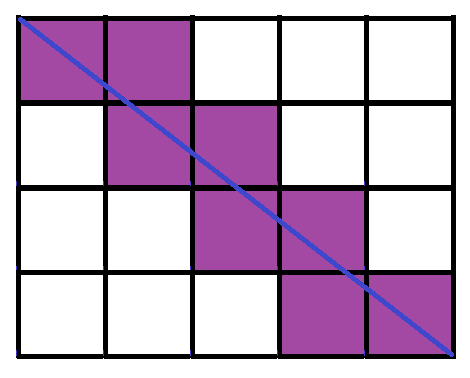
8 sliced squares
Okay, so the number of sliced squares seems to be increasing by 1 for every increase in width. At this point, intuition tells that it can be very difficult to come up with a pattern that encompass two variables by drawing pictures with, in reality, only one variable. Any apparent consequent pattern about the change in either length, or width(only one at a time) is inconclusive, especially with the fact that the illustrations can be rotated ninety degrees, and then the pattern for previous length does not apply for the "new" length.
Plan B:
Perhaps the most difficult part of this plan was finding a way to distinguish the whole squares from the incomplete squares. My friend's observation of the problem's resemblance to integration has significantly advanced our progress. The connection is shown below.
This:
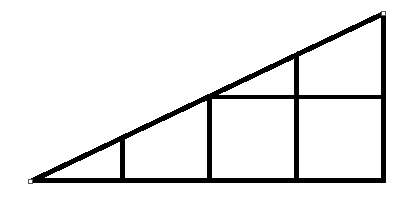
Becomes:
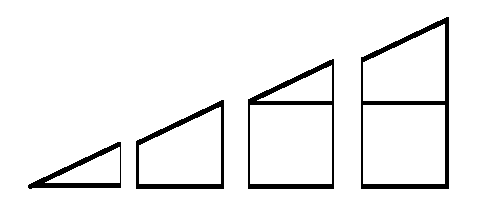
Then, it is clear to see how to calculate the number of complete squares inside the triangle; all we need to do is look at the shorter side of each shape, and the floor of that length will produce the number of complete squares inside that shape. The length of each side of the shape can be written as a function to its place (starting from 0) in the triangle as f(x) = mx, where m is the slope of the hypotenuse of the triangle. So for the example above, the slope can be calculated by rise over run: 2 / 4 = (1/2). Then, the shortest side for the first shape is at position 0, thus its height is f(0) = (1/2)(0)=0. Then we know there is no complete square in the first shape. For the second shape, f(1) = 1/2, and the floor of 1/2 is 0, so there is still no square. For the third one, f(2) = 1, and floor(1) = 1, so there is one square present. Lastly, for the fourth one, f(3) = 3/2, and floor(3/2) = 1, so there is one square. In total, we have seen 2 complete squares. Since the total number of squares in a 4 by 2 rectangular grid is 4*2 = 8, then the number of sliced squares, (the formula was mentioned in Devising a plan: Plan B) 8 - 2(2) = 4.
We used summation to devise a formula that represents this method:
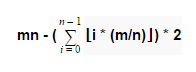
Where m is the width of the rectangular grid, and n is the length of the rectangular grid. Note that this formula only works if the diagonal line is drawn from the bottom left corner to the top right corner, so the shorter length of each shape inside the triangle is calculated.
4. Looking back
We can check the result by plugging in m and n for a few examples shown in Carrying out the plan: Plan A.
For a 2 by 2 rectangle, the formula gives us 2 * 2 - (⌊0 * (2/2)⌋ + ⌊1 * (2/2)⌋) * 2 = 2, which matches the illustration.
For a 3 by 2 rectangle, the formula gives us 3 * 2 - (⌊0 * (2/3)⌋ + ⌊1 * (2/3)⌋ + ⌊2 * (2/3)⌋) * 2 = 4, which matches the illustration.
For a 5 by 3 rectangle, the formula gives us 5 * 3 - (⌊0 * (3/5)⌋ + ⌊1 * (3/5)⌋ + ⌊2 * (3/5)⌋ + ⌊3 * (3/5)⌋ + ⌊4 * (3/5)⌋) * 2 = 7, which matches the illustration.
We tunneled through to this solution once we figured out how to calculate the number of complete squares inside a triangle, so we probably would not have reached the same solution easily with another approach.
Similar methods can be used to solve this type of problem encountered in computer graphics or video game design that involve the particular concept of this problem.